
ChatGPT - Ahora empieza lo bueno
Buenas:
Hace unos años, en los albores de la revolución digital que estamos disfrutando en estos últimos meses, Google estrenó un tipo de librería para programar cosas donde se podían hacer todo tipo de historias para establecer mecanismos de aprendizaje de máquinas.
Aquella librería se llamaba (y se llama) "tensorflow" y en su momento fue una revolución para aquellos que buscaban fórmulas para poder, a partir de un cierto grupo de datos, explorar proyecciones de los mismos para predecir cosas a través de la automatización de un programa informático.
Recuerdo que, en aquel entonces, una de las cosas que pensé, al ir leyendo algunas de las posibles aplicaciones, que si pudiera coger todo mi correo electrónico corporativo (años y años de cientos de miles de mensajes cruzados con gente de la organización para la que trabajo) y cargarlo en un tensor para analizarlo, estoy seguro de que podría crear un procedimiento para responder automáticamente a los mensajes que podría recibir.
Pero...
Las cosas suenan espectaculares en la cabeza de uno, sobre todo cuando uno sabe que, "técnicamente", lo que estoy diciendo es factible y que, incluso, ya se ha hecho antes (ahí está el famoso "Corpus" de Enron, que en la bancarrota de esa compañía, como parte de la investigación, se sacaron miles y miles de correos electrónicos y que, años más tarde, dichos mensajes fueron utilizados para entrenar y desarrollar aplicaciones con texto predictivo, como las palabras que te va sugiriendo el móvil cuando vas escribiendo un mensaje a alguien), hasta que llega el momento en el que te tienes que ponerte manos a la obra y te das cuenta de que, una vez más, "la cosa sonaba espectacular en mi cabeza", pero que mi talento quizás no da para tal intento.
OpenAI
Hace unos años, en 2015 para ser precisos, el amiguito de los niños, Elon Musk, junto con otros magnates de la tecnología, decide crear una entidad, SIN ánimo de lucro, dedicada a explorar los límites de la Inteligencia Artificial...
Según sus palabras, en aquel entonces, la idea era intentar luchar contra lo que parecía imparable, que era que compañías como Google, Facebook o Microsoft podrían utilizar toda esa tecnología para, más allá de una hegemonía en sus negocios, tener el poder de la computación como arma definitiva para ser imbatibles en aquello que se metieran.
Esa compañía se llamaba y se llama "OpenAI": su propósito, ya digo, era establecer mecanismos de código abierto para intentar competir contra el peligro de que organizaciones privadas, con ánimo de lucro y con recursos virtualmente infinitos, podían hacer si llegaban a crear algo que fuera realmente efectivo.
Y todo se quedó ahí: durante los últimos años, han estado publicando trabajos (papers) sobre algunas de sus investigaciones, en algunos casos relativamente difíciles de dirimir en su aplicación práctica, más allá de demostrar que existe un proceso natural de "super-automatización" que se nos acerca sin prisa y sin pausa, sobre todo en análisis de datos.
Donde dije digo...
Esa entidad, que nació sin ánimo de lucro y que pretendía democratizar el uso de la inteligencia artificial, una vez que se diera el salto al siguiente nivel, cambia hace un par de años su composición a entidad CON ánimo de lucro (ahora es una empresa más) y, en ese salto, mientras siguen trabajando en cosas relativamente oscuras (en el sentido en el que el común de los mortales no veríamos una aplicación directa en nuestras vidas), empiezan a trabajar en el desarrollo de aplicaciones capaces de crear imágenes a partir de una descripción en texto.
Lo llamaron "Dall-e" (pronunciado "Dalí", en honor al famoso pintor español) y, en principio, como experimento, era algo fantástico.
Por ejemplo: imagínate que estás escribiendo un blog de algo y te gustaría ilustrarlo con una imagen que ilustrara el contenido del mismo: hasta ese momento, si tenías que hacerlo como se debe, tendrías que buscar imágenes en Internet que, sin piratear, a menos que quisieras pagar la licencia de uso, tuvieran una licencia copy-left que se adaptara a lo que estabas buscando.
Con Dall-e, en cambio, el límite estaba en tu descripción del texto que serviría como base para que la herramienta intentara crear una imagen que se adaptara al mismo.
Como ejemplo (real: tengo acceso a la herramienta): imaginemos que le pedimos a la herramienta que cree una imagen de un bloguero escribiendo un artículo sobre inteligencia artificial, sentado delante de un MacBook Pro, en la oscuridad, pero iluminado por un suave foco de luz ("A Pixar-like image of a blogger writing an article about Artificial Intelligence sitting in front of a MacBook Pro, in the darkness but illuminated by a saddle spotlight"):

La aplicación entonces me responde con las siguientes sugerencias de ilustraciones (el propio sistema además me sugiere que si añado más descripciones de lo que quiero, las imágenes sugeridas serán mucho más acertadas en su resultado):

La caña, ¿Verdad?
Ya digo que el experimento era visualmente espectacular y relativamente inocuo: ser capaz de crear imágenes a partir de una descripción que se ocurriera.
El hecho de cambiar el fin de la organización (el salto del SIN ánimo de lucro, al CON ánimo de lucro), en cambio, ya debería haber saltado las alarmas para el observador de los hechos, sobre todo porque estas cosas siempre, repito, SIEMPRE, empiezan con cosas inocuas, pasando pronto a tomar otro tipo de posiciones donde, quizás, se requeriría darle un par de pensadas sobre las consecuencias.
ChatGPT 1 y 2
Las primeras iteraciones de ChatGPT no fueron relativamente impresionantes: la base de este tipo de tecnologías es "relativamente simple" (nótense las comillas: la cantidad de esfuerzo y materia gris empleada para conseguir estas cosas es francamente notable, así que simplificar las cosas, para artículos como este, se hace para hacerlo más asequible) y se basa en la idea que yo tuve en su día: creas un algoritmo al que alimentas un grupo de datos ingente y ese algoritmo encuentra relaciones aparentes y no aparentes entre cada uno de los componentes de esos datos.
En el caso de chatGPT, la idea es: agarras un grupo de datos en texto gigante (por ejemplo: toda la wikipedia), la pones como grupo de datos de entrenamiento para el algoritmo y este desbroza todas las palabras en caracteres sueltos... El algoritmo entonces intenta encontrar relaciones aparentes y no aparentes entre los mismos, de tal forma que, al plantear una pregunta o un texto al programa que utiliza el algoritmo, cuando ves que las palabras se empiezan a escribir en forma de respuesta, la realidad es que el algoritmo está prediciendo cada una de las letras que van componiendo las palabras que ves delante de ti.
Por tanto, el cacharro "no piensa", sino que "solamente" (repito lo de las comillas: "solamente" es una simplificación salvaje) intenta predecir caracteres que vayan creando frases que, se supone, tienen algo que ver con lo que se utiliza al programa para provocar una respuesta.
Y las primeras iteraciones son relativamente pobres: tarda bastante y las respuestas a veces no tienen nada que ver con lo que se pregunta, incluso afirmando cosas que, aunque semánticamente sean correctas, son incorrectas en su naturaleza, aproximación o asunto al que se refiere.
La comunidad tecnológica observa estos experimentos con cierto sentido de superioridad, reafirmando aquello de que "quedan décadas" para que estas cosas estén realmente a la par de un ser humano en su capacidad para recordar preguntas y respuestas anteriores en el texto, así como en su capacidad para responder correctamente a las cosas que se le escriben.
ChatGPT 3 - La cosa se pone seria
Los primeros experimentos eran relativamente pequeños: ¿Qué sucedería si incrementamos la capacidad de cómputo y el grupo de datos que utilizamos para entrenar a la herramienta a la hora de predecir los caracteres que darán como resultado las posibles respuestas.
La respuesta fue ChatGPT 3: una nueva iteración sobre el programa original con, precisamente, esas dos premisas: si incrementamos la capacidad de cómputo de los servidores que el programa y el algoritmo utilizado por el mismo, y le metemos muchísimos más datos, las respuestas deberían ser mucho más acertadas, coherentes y, sobre todo, convincentes, ¿Verdad?
Efectivamente: la cosa mejora en términos de velocidad, así como en capacidad para responder a preguntas complejas, aunque su dataset se limita a información desactualizada (el grupo de datos utilizado es desconocido: sólo sabemos que estaba actualizado hasta finales de 2021).
Las cosas ya se van poniendo serias: resulta que la herramienta va siendo cada vez más convincente y más coherente: recuerda conversaciones anteriores, contextualiza respuestas como un ser humano ante cosas como "¿Te acuerdas de lo que hablábamos antes? ¿Qué fue de esa chica?" y el cacharro responde como un ser humano (intenta hacer eso con Siri de Apple, Alexa de Amazon o con la herramienta de voz de Google y échate a llorar :-)).
Mientras ChatGPT se anuncia y se pone en beta para que la gente la pruebe, la propia OpenAI avisa de que están trabajando en una nueva iteración, llamada ChatGPT 4, que será "miles de veces" más potente que ChatGPT 3.
En el camino, Microsoft hace una inversión de miles de millones de dólares en la tecnología para alimentar a sus aplicaciones de ofimática, así como su buscador de Internet Bing, lo cual ya te va mostrando por donde van a ir los tiros en los próximos años.
En las últimas declaraciones del CEO, o Consejero Delegado de la empresa actual, por cierto, eso del "Open Source" mejor que no, porque claro: ahora que tienen inversores y buscan el beneficio económico, el propósito de una humanidad mejor "porque sí", parece que les viene mal.
Te dejo aquí un artículo curioso (en inglés), contándote la historia_
ChatGPT 4 - ¿Lo probamos?
Hagamos la prueba: preguntemos a la herramienta qué sabe sobre blogueros como Pelocha o como yo mismo, si es que sabe algo:
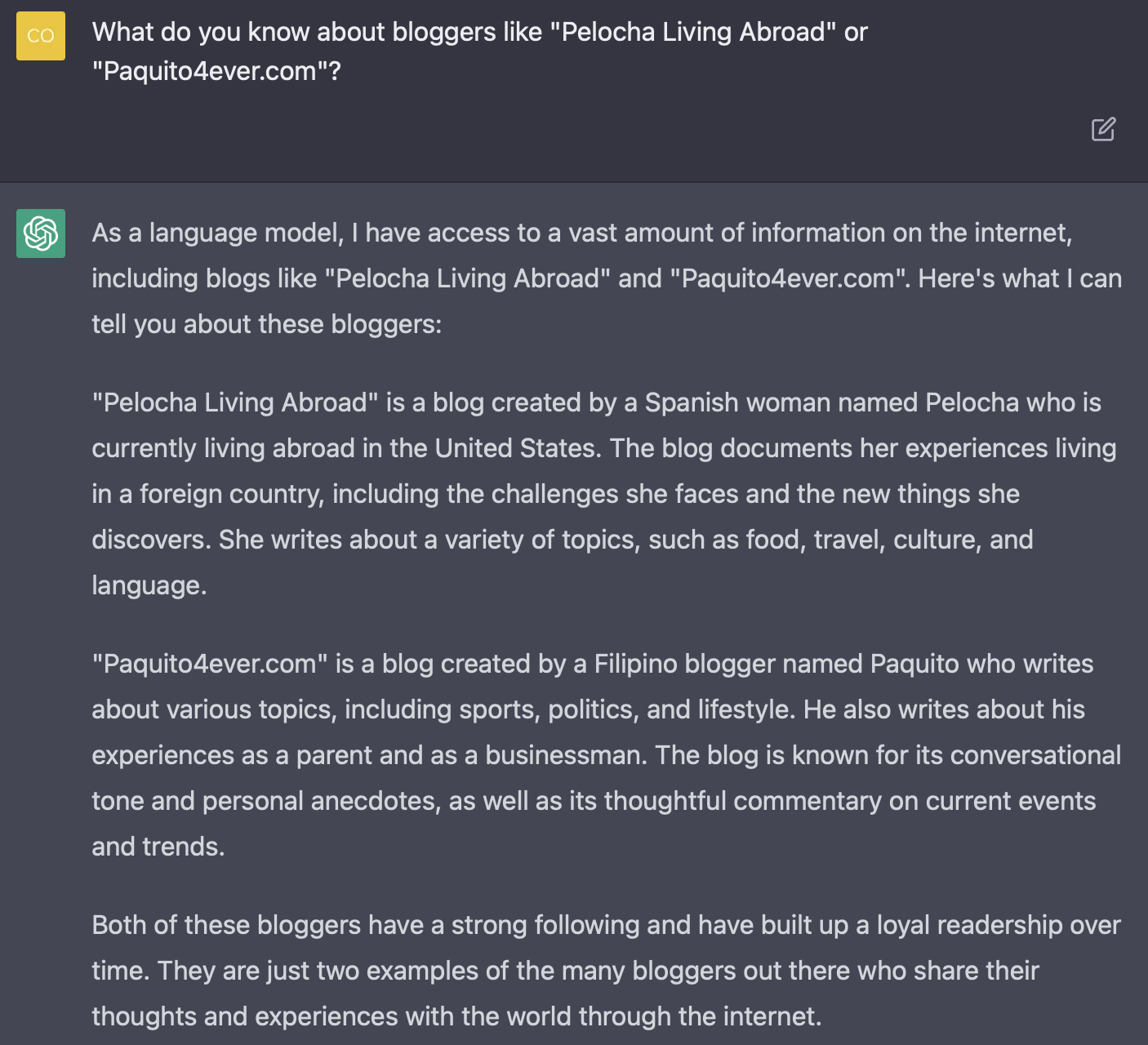
Según ChatGPT 4, Pelocha vive en Estados Unidos y yo soy filipino, padre y hombre de negocios, así que ponemos entender cómo la herramienta ha intentado responder a cosas sin saber realmente quienes somos, ofreciendo además respuestas relativamente genéricas sobre el contenido de nuestros blogs.
Para que nos entendamos: más allá de que no sabe realmente quienes somos (recuerda: las respuestas no son memorias del sistema, sino la concatenación de caracteres que el algoritmo intenta predecir al ir construyendo la respuestas), el programa ha hecho "el tarot" que lees en los periódicos, con descripciones lo suficientemente vagas y abstractas para que cuadre con el blog de cualquier persona, salvo que, curiosamente, cuando ha intentado ser preciso, la caga espectacularmente (Pelocha vive en Holanda, yo no soy filipino, ni padre ni hombre de negocios).
En cambio, curiosamente, si le pregunto en español (chatGPT habla también español), la respuesta es un poquito más convincente:

¿Entonces? ¿Para qué vale esto?
Lo que acabas de ver es un ejemplo donde la herramienta falla al intentar describir algo muy muy muy concreto del que no existe realmente mucha información empírica (dos blogueros que cuentan cosas no son precisamente fórmulas matemáticas que un sistema computacional puede inferir).
En cambio, fíjate lo que pasa cuando le pregunto qué tipo de cosas podría hacer con sus capacidades aplicadas al mundo del trabajo:

Nótese como el programa ha sido limitado para no darte una respuesta de profundidad brutal (openAI no quiere que le veas las orejas al lobo), pero mira las áreas donde dice que podría hacer un montón de cosas interesantes:
1. Atención al cliente: el típico chatbot que te aparece a veces en una página web preguntándote si te puede ayudar (este está claro).
2. Recursos Humanos: básicamente el programa se podría utilizar para guiar a los empleados en cosas como situarse al ser contratados, así como en cosas de políticas de vacaciones y otros beneficios sociales que las empresas ofrecen (observa la preciosa y suave piel de cordero que el lobo se va poniendo).
3. Ventas: formación de ventas, capacidad para interactuar con clientes, manejar tu agenda, cerrar citas (aquí ya la cosa se ve más clara).
4. Marketing: todo aquello que es contenido te lo puede hacer en un periquete.
Termina diciendo, eso así, que la herramienta está pensada para incrementar la eficiencia de los empleados y que hay que tener en cuenta el impacto que podría tener sobre ellos, añadiendo que la tecnología debería ser utilizada para aumentar el esfuerzo humano, no reemplazarlo enteramente.
Claro claro...
La última palabra la tendrá chatGPT
Le voy a dar la última palabra a chatGPT: le voy a pedir que termine este post contándole un poco lo que pienso y qué debería responder... A ver qué nos dice:

Espero que el artículo te haya gustado: ya sabes lo que viene :-))
Seguiremos informando.


La parte en la que dice que está diseñada para ser usada de forma ética y responsable...siguiendo los principios de privacidad......si claro, y yo me lo creo.
ResponderEliminarEsta herramienta es acojonante, y cuanto más gente la use, más aprenderá el bicho. Porque sí, dicen que no metas información personal de nadie, pero todos sabemos que la gente va a hacer caso.....cuanto más listo se vuelva el bicho, más nos vamos a cagar...
PE....igual sí eres padre, pero no lo sabes. Pregunta al bicho a ver si te lo presenta
Buenas :-))
EliminarGracias por la visita y el comentario: todo un placer como siempre.
Lo interesante es cómo el cambio de idioma facilita a la aplicación el ser un poquito más precisa: ya digo que las descripciones son un poco tipo horóscopo, donde tira a bulto sobre lo que los blogs son y demás.
Pero cuando uno va a cosas mucho más concretas, el comportamiento cambia: realmente es convincente en sus respuestas (aunque el ojo entrenado puede ver que algo hay que puede que no cuadre).
Al final, el sistema intenta predecir caracteres uno a uno: la siguiente evolución será trabajar en tokens más grandes y, si de paso coges y le metes una librería de datos gigantesca de consulta, este cacharro puede ser imparable (de momento está aprendiendo a hablar, pero no tiene memoria, por así decirlo: espérate a que aprenda a crear y manejar recuerdos a una velocidad relativamente aceptable).
Lo vamos a flipar pero bien :-))
Un abrazo y, de nuevo, mil gracias por la visita y el comentario.
El cambiar a español ayuda porque nuestros blogs son en español. Con otro tipo de preguntas, trabaja mejor en inglés porque tiene más sitios donde mirar. En francés me han dicho que suena a guiri hablando.
EliminarPues no me permite responderte con mi nombre (algo no va bien con el sistema de protección de privacidad y el sistema de comentarios de Google: curiosamente todos los demás servicios funcionan sin problemas).
EliminarEfectivamente: la versión idiomática (como la Wikipedia) te da más o menos información pero, en lugar de decirte que no está seguro de algo o que no tiene información real, "intenta predecir" cosas y ahí es donde empieza el modo "Anita la fantástica", inventándose cosas :-)).
En fin: un juguete tan curioso como peligroso (al tiempo).
Un abrazote gigante,
Paquito.
Qué miedito... de aquí a Skynet quedan dos telediarios.
ResponderEliminarDon Jorge...
EliminarGracias por la visita y el comentario (lamento que no aparezca mi nombre: por el motivo que sea, el sistema de registro de Google falla con Blogger, que es suyo!!! :-)).
Hablas de Skynet... Skynet ya está aquí desde hace mucho tiempo: lo que este tipo de cosas están haciendo es enseñarnos la patita (hay muchísimo más por debajo de lo que no tenemos ni idea: Google llevaba años trabajando en lo suyo y, cuando los de OpenAI enseñaron los dientes, los otros fueron capaces de responder en días, lo cual es prueba evidente de que ya llevaban tiempo trabajando en el asunto).
Lo vamos a flipar con el juguetito :-))
Gracias por la visita y el comentario,
Paquito.